Python爬虫实战—vmgrils图片网站
本文共 2238 字,大约阅读时间需要 7 分钟。
一、实战背景
唯美女生:
少女情怀总是诗,一双发现美的眼睛!
工具:Python3.7,PyCharm
程序所需用到的模块:requests,fake_useragent,parsel,os,time
所使用的解析器:xpath
二、明确目标
明确我们需要爬取哪个图片集的图片资源,这里以少女情怀总是诗为例。
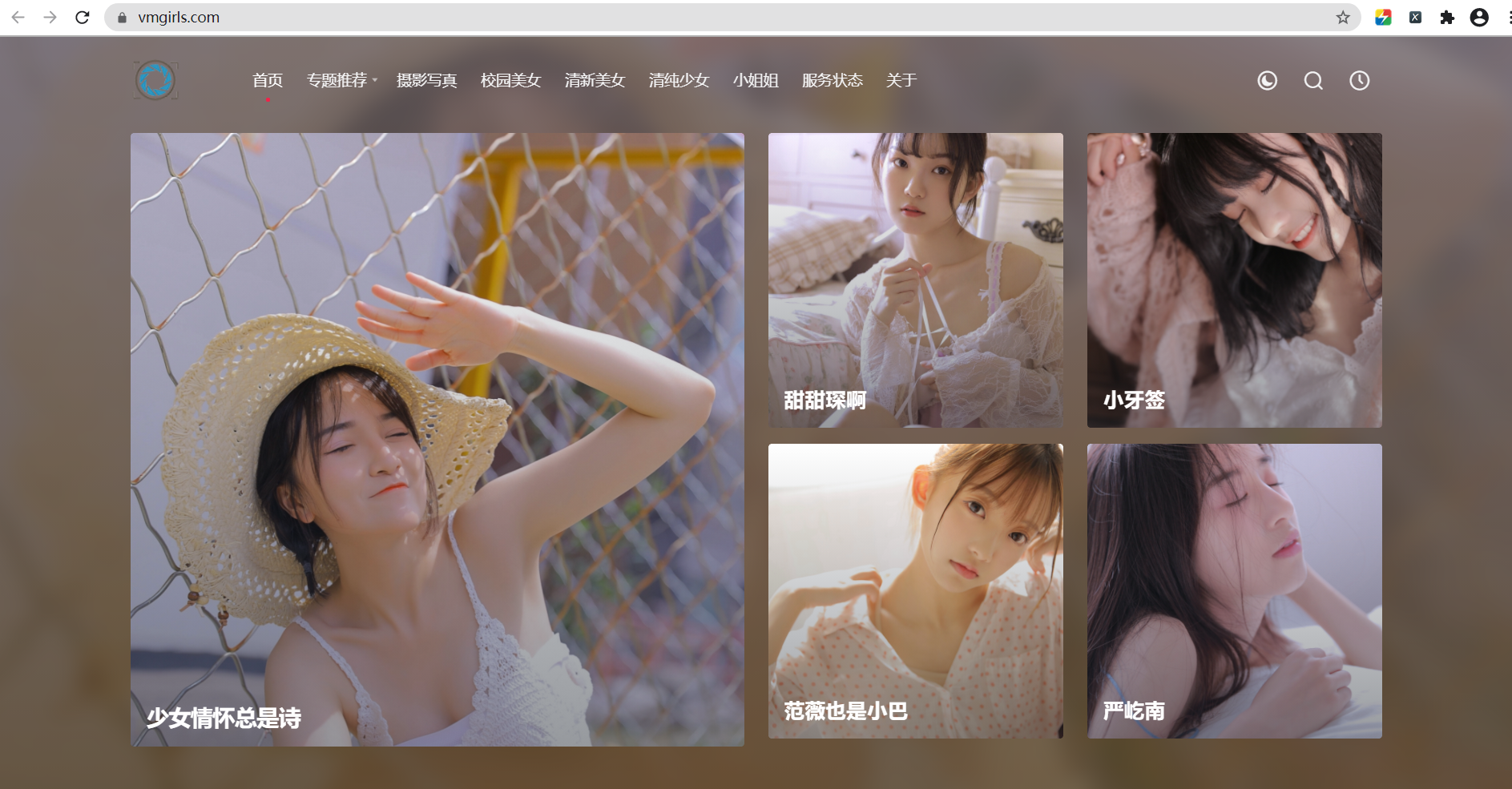
2.1 分析我们需要爬取的图片链接地址
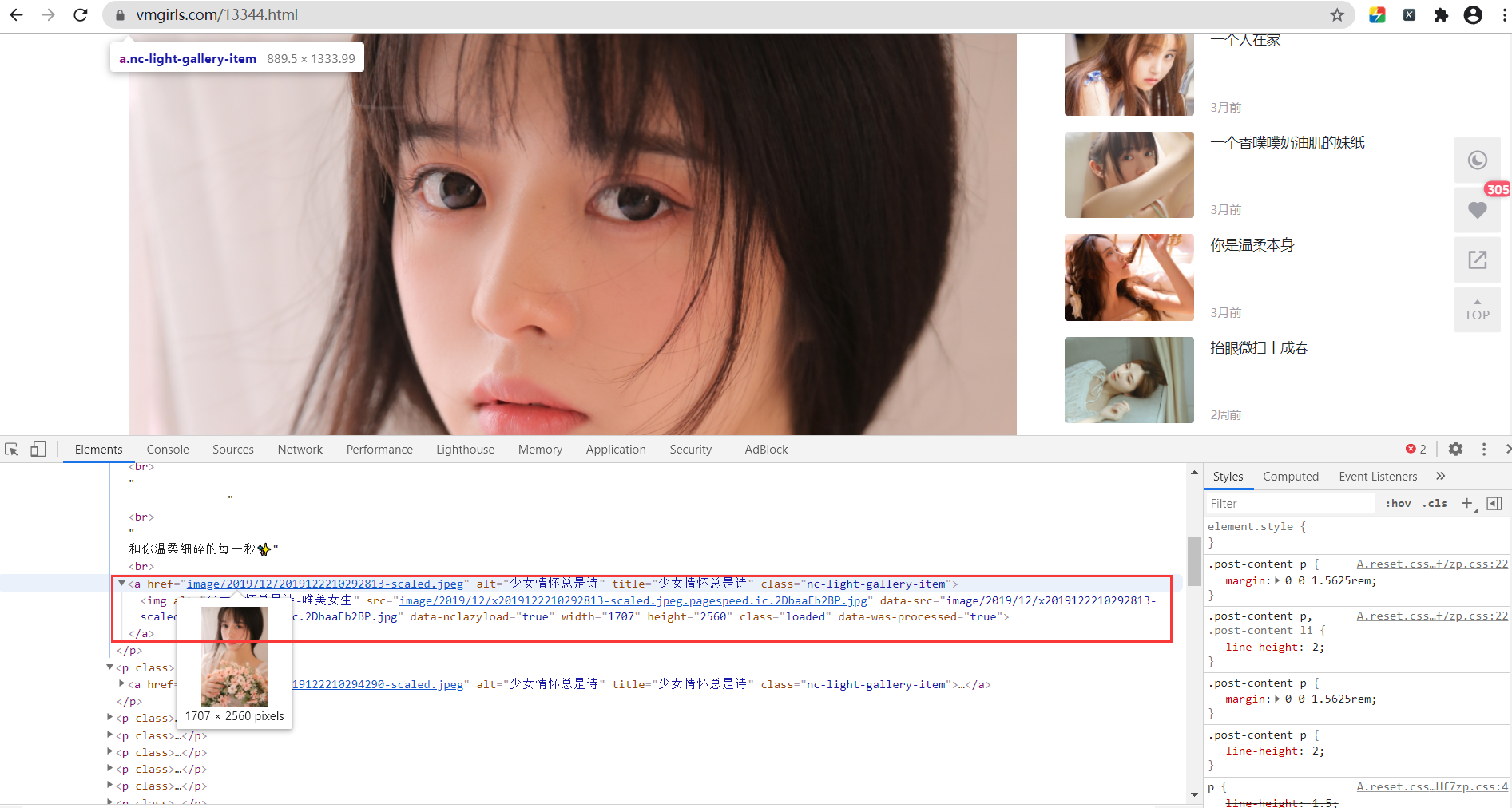
按F12打开开发者工具
这里可以看见,选择 a 标签中的 href 属性或者 img 标签中的 src 属性都是可以的,我这里就选择 a 标签中的 href属性
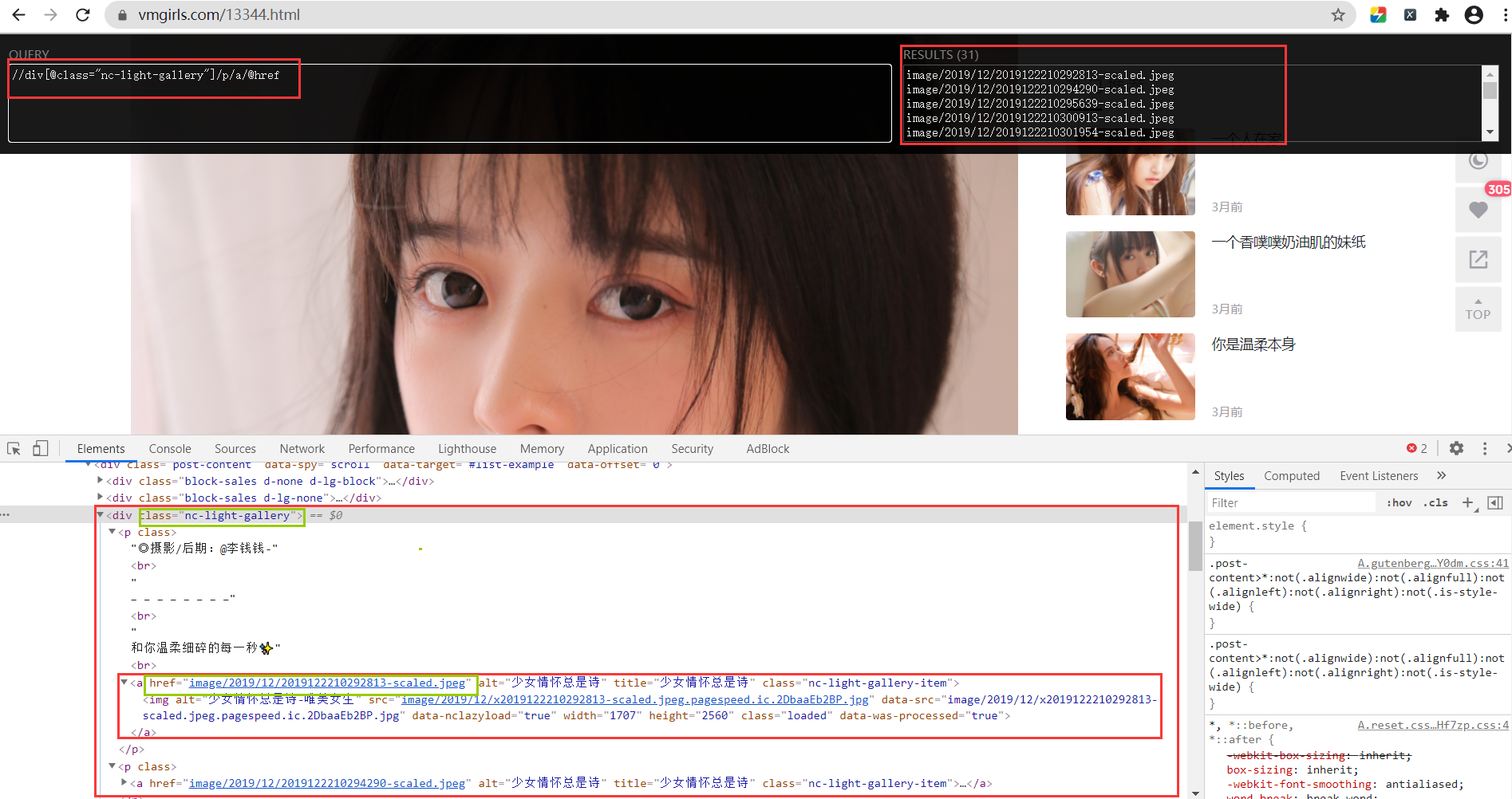
2.2 分析节点,使用xpath解析器审查元素
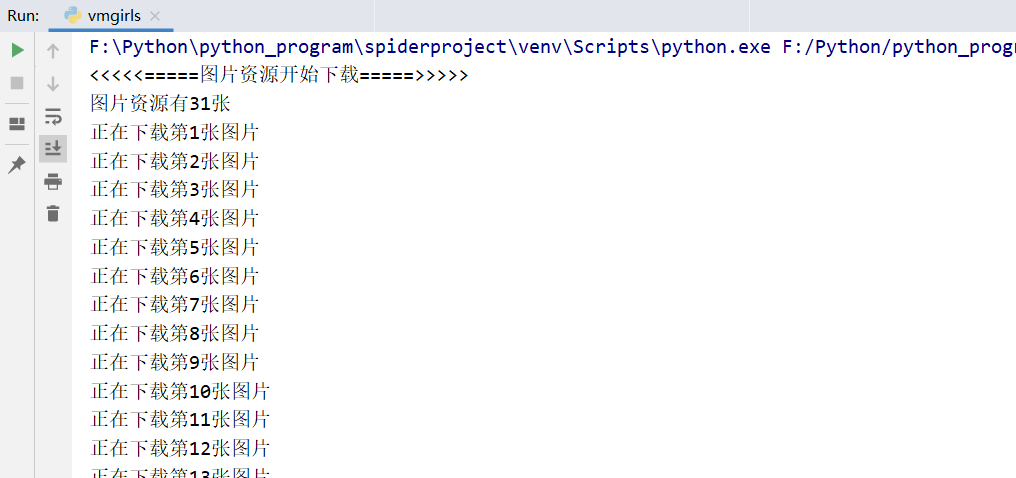
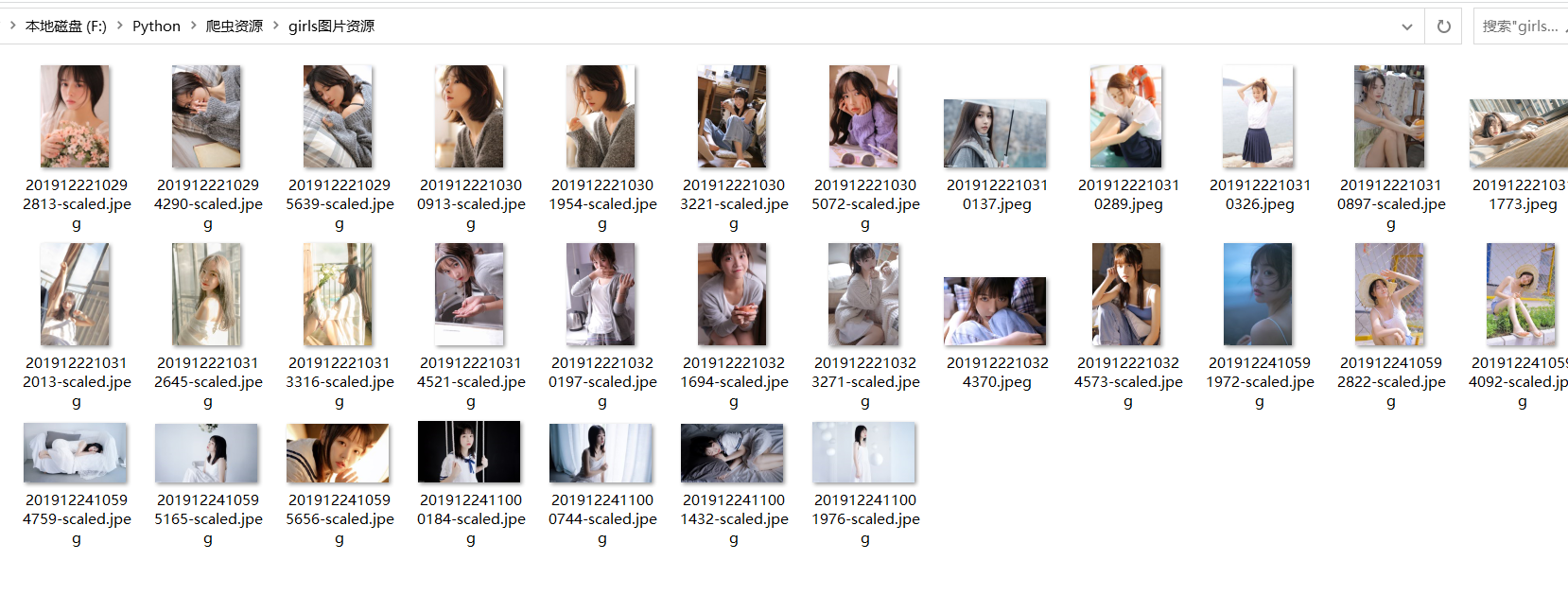
三、编写代码
""" Python爬取 https://www.vmgirls.com/ 网站的图片"""import requestsfrom fake_useragent import UserAgentimport parselimport timeimport osclass VmGirlsPhotos(object): """ 类说明:下载 vmgirls图片网站的《少女情怀总是诗》图集 """ def __init__(self): self.server = "https://www.vmgirls.com/" self.target = "https://www.vmgirls.com/13344.html" self.headers = { "User-Agent": UserAgent().random} self.dir_name = "F:\Python\爬虫资源\girls图片资源\\" self.urls = [] # 存放图片链接地址 def isDir_existed(self): """ 函数说明:判断当前目录是否存在,没有则创建 :return: """ if not os.path.exists(self.dir_name): os.mkdir(self.dir_name) def get_urls(self): """ 函数说明:获取每张图片的链接 :return: """ """ 请求网页 """ response = requests.get(url=self.target, headers=self.headers) html = response.text """ 解析网页 """ selector = parsel.Selector(html) # 返回的是所有的图片链接地址的列表 url_list = selector.xpath('.//div[@class="nc-light-gallery"]/p/a/@href').getall() for url in url_list: self.urls.append(self.server + url) def write(self, dir_name, url): """ 函数说明:下载图片 :return: """ # https://www.vmgirls.com/image/2019/12/2019122411001976-scaled.jpeg # 2019122411001976-scaled.jpeg 就作为保存图片的名称 fileName = url.split('/')[-1] response = requests.get(url=url, headers=self.headers) with open(dir_name + fileName, 'wb') as file: file.write(response.content) file.close()if __name__ == '__main__': print("<<<<<=====图片资源开始下载=====>>>>>") vp = VmGirlsPhotos() vp.isDir_existed() vp.get_urls() print("图片资源有{}张".format(len(vp.urls))) for i in range(len(vp.urls)): vp.write(vp.dir_name, vp.urls[i]) print("正在下载第{}张图片".format(str(i + 1))) time.sleep(1) print("<<<<<=====图片资源下载完成=====>>>>>") 四、效果展示
![开车吗表情包 [什么时候开车?我营养跟得上]](https://img-blog.csdnimg.cn/img_convert/647fcd3e0f24ac9f6b1f64acc982f3ba.png)
做一个文明守法的好网民,不要爬取公民的隐私数据,不要给对方的系统带来不必要的麻烦
此篇博客仅作学习用途
转载地址:http://tkiwi.baihongyu.com/
你可能感兴趣的文章
postgresql计算两点距离(经纬度地理位置)
查看>>
postgres多边形存储--解决 Points of LinearRing do not form a closed linestring
查看>>
postgresql+postgis空间数据库总结
查看>>
spring 之 Http Cache 和 Etag(转)
查看>>
基于Lucene查询原理分析Elasticsearch的性能(转)
查看>>
HttpClient请求外部服务器NoHttpResponseException
查看>>
springCloud升级到Finchley.RELEASE,SpringBoot升级到2.0.4
查看>>
Spring boot + Arthas
查看>>
omitted for duplicate jar包冲突排查
查看>>
如何保证缓存与数据库的双写一致性?
查看>>
java.lang.ArrayStoreException: sun.reflect.annotation.TypeNotPresentExceptionProxy排查
查看>>
深浅拷贝,深浅克隆clone
查看>>
Java基础零散技术(笔记)
查看>>
Mysql优化sql排查EXPLAIN EXTENDED
查看>>
线程之间数据传递ThreadLocal,InheritableThreadLocal,TransmittableThreadLocal
查看>>
spring循环依赖,解决beans in the application context form a cycle
查看>>
分布式锁的实现
查看>>
解决POJO的属性首字母为大写,但是赋值不了的问题
查看>>
服务器运维整理(笔记)
查看>>
redis分布式锁在MySQL事务代码中使用,没控制好并发原因
查看>>